Identiscentory -Sonic- (Wick Woodland Edition)
Identiscentory –Sonic– is an olfactory and auditory spatial endeavour to foster a collective narrative space. It explores the potential of using invisible senses enabling the sharing and storytelling of individual experiences. This project responds to the question, “How do people perceive narratives through sensory experiences?”
We employ intersemiotic translation, using olfaction as an unseen catalyst that triggers people’s narratives through environmental scents, tailoring the spatial experience to site-specific. Whether in natural settings like forests or human-made places like temples, each locale possesses distinct scents capable of evoking unconscious memories. The verbal olfactory narratives expressed by the audiences are transformed into musical compositions, a combination of AI analysis of textual content’s meaning and audio characteristics of voices to customize music aligned with the narratives presented in real time. Audiences can explore the collective narratives in the space, moving linearly and experiencing the transition from original linguistic expressions to translated music.
The dual experiences offered by Identiscentory –Sonic– enable audiences to share their narratives while simultaneously engaging with the stories of others, all originating from one scent. The project can further develop into a collective narrative environment for the targeted group where the olfactory prompt resonates with their cultural background. A singular element expands into an expansive sea of collective narratives, where individuals perceive narratives through multifaceted sensory encounters.
YEAR
2023 - 2024
GENRE
Sonic Spatial Experience
EXHIBITION
Bartlett Fifteen Show @ Bartlett School of Architecture (London, United Kingdom)
DFPI Project Fair @ UCL at Here East (London, United Kingdom)
COLLABORATION
Jaewon You (August - November 2023)
















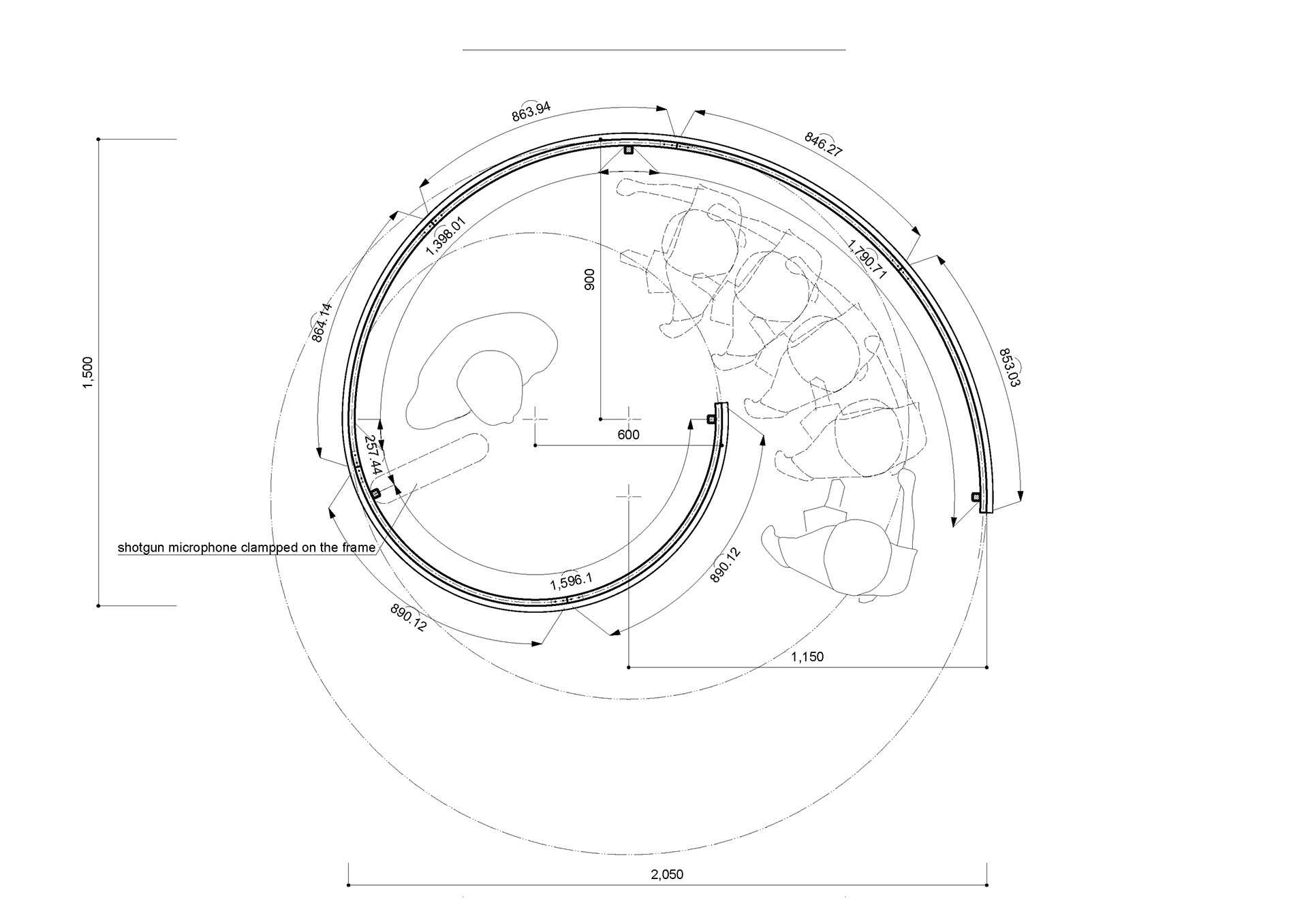
SKETCH
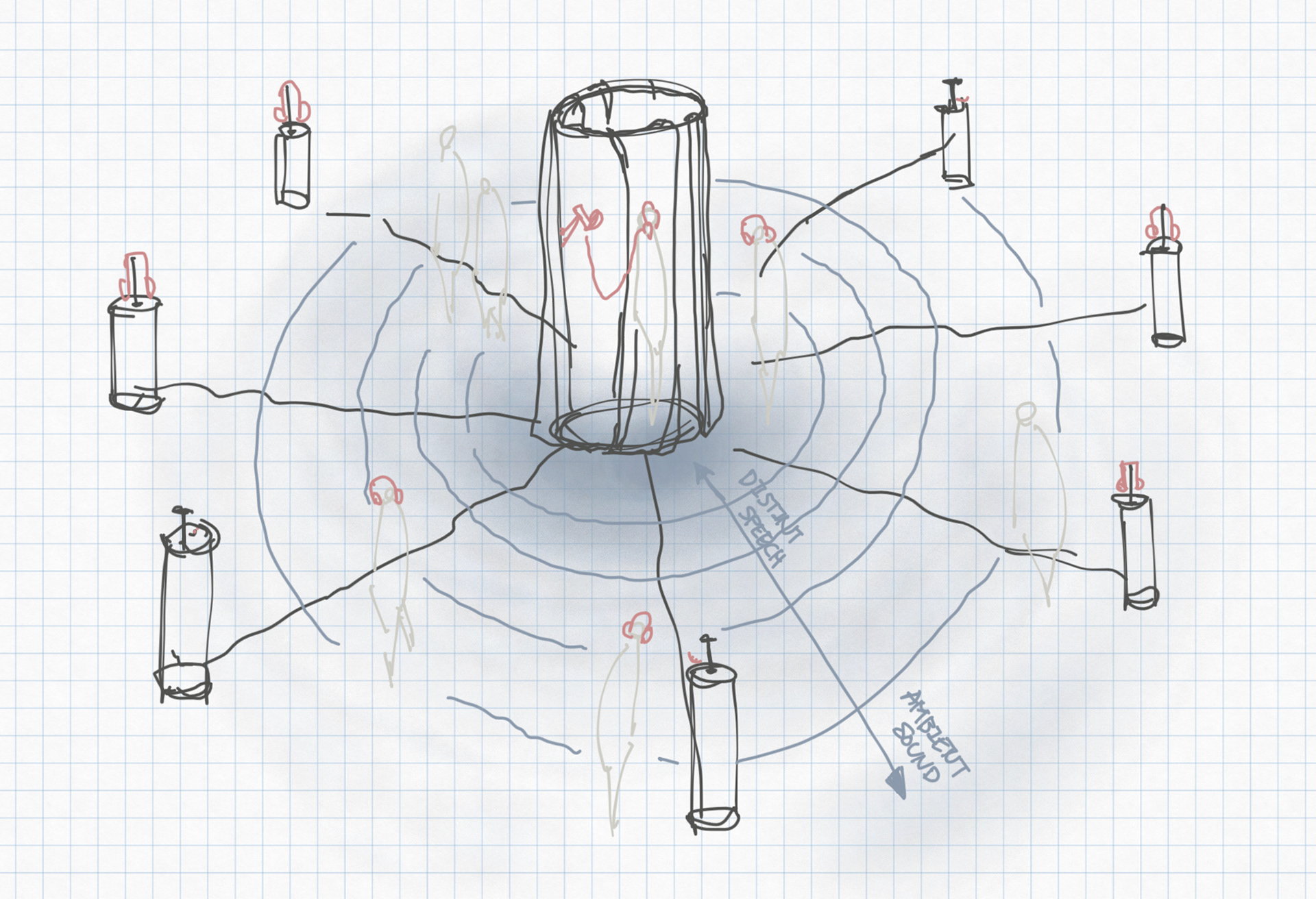

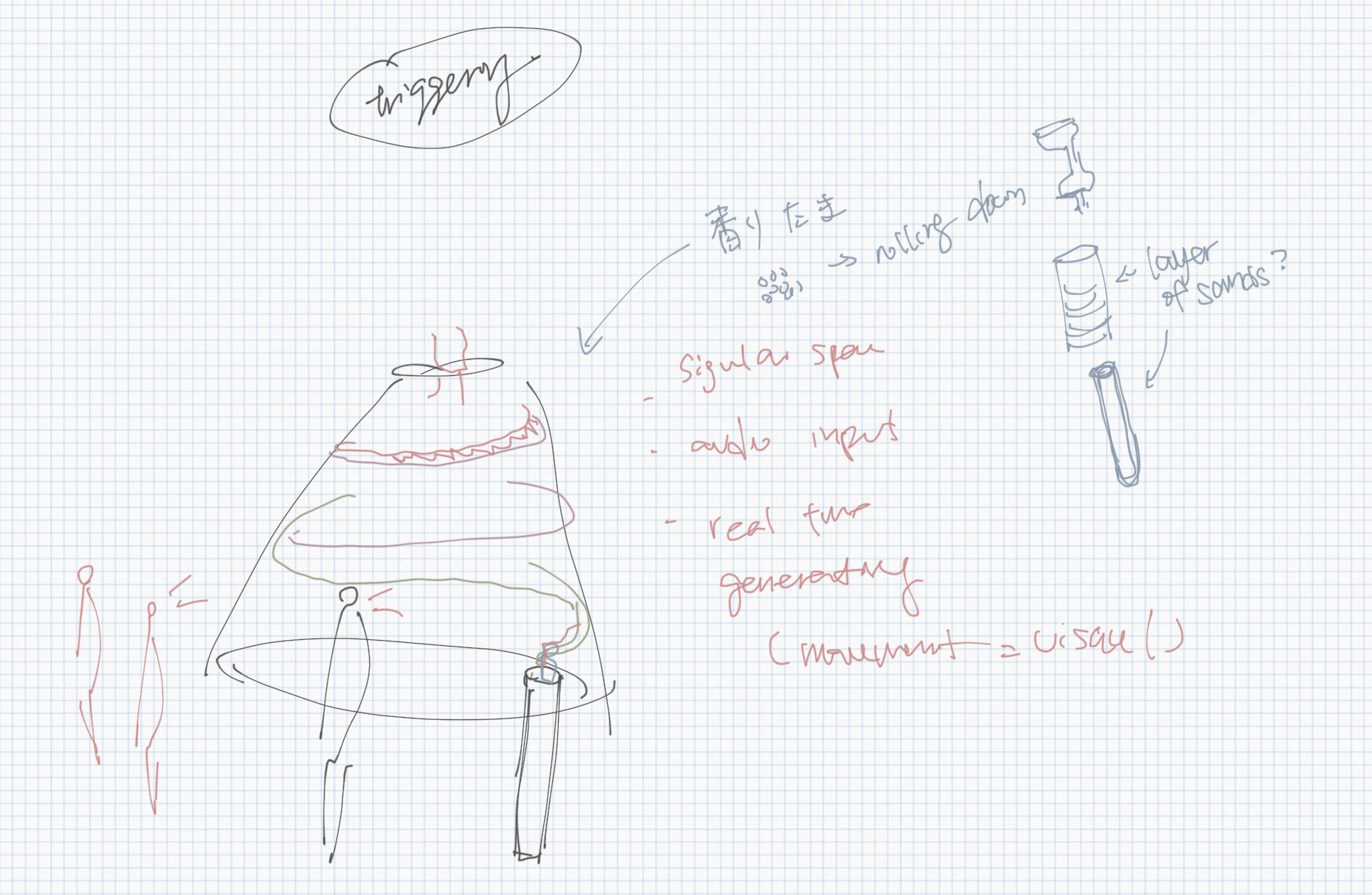
diagram
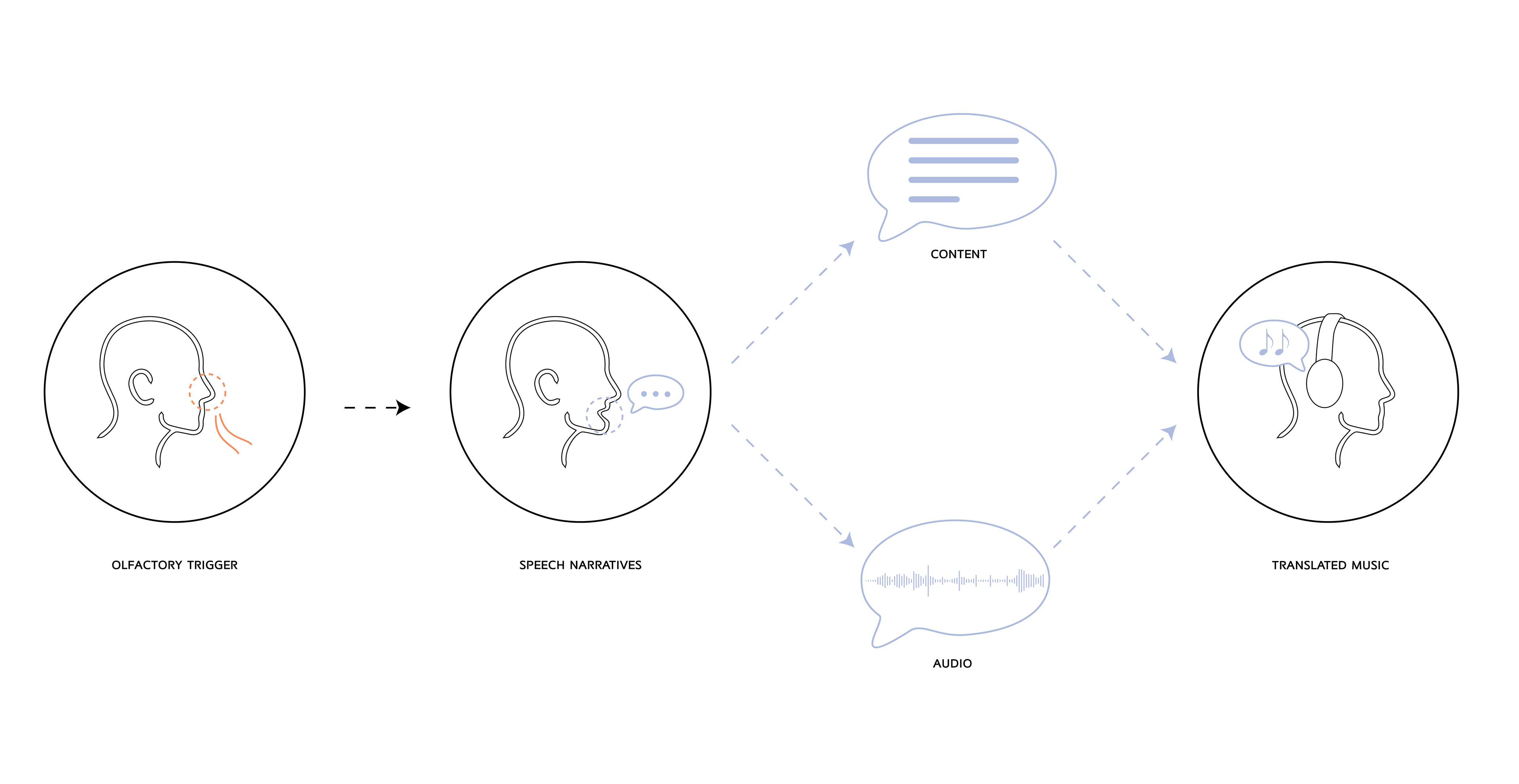

The exploration of audio in space and its relationship with site-specific olfactory experiences resulted in layers of translation.
By analyzing the audio narratives (the story) of participants through speech content (text-based) and audio texture (audio-based), the final output of translated music reflects individuality within a specific time and place.
The audio narrative is first analyzed by AI tools - Whisper and Music Gen - to transform its audio from multilanguage models into text format. The text is then analyzed to translate it into musical form.
At the same time, the audio narrative is analyzed by TouchDesigner through its audio characteristics, such as speech frequency. The extracted audio data is then applied to the translated music piece from the AI, eventually creating a corresponding music piece to the original speech narrative.
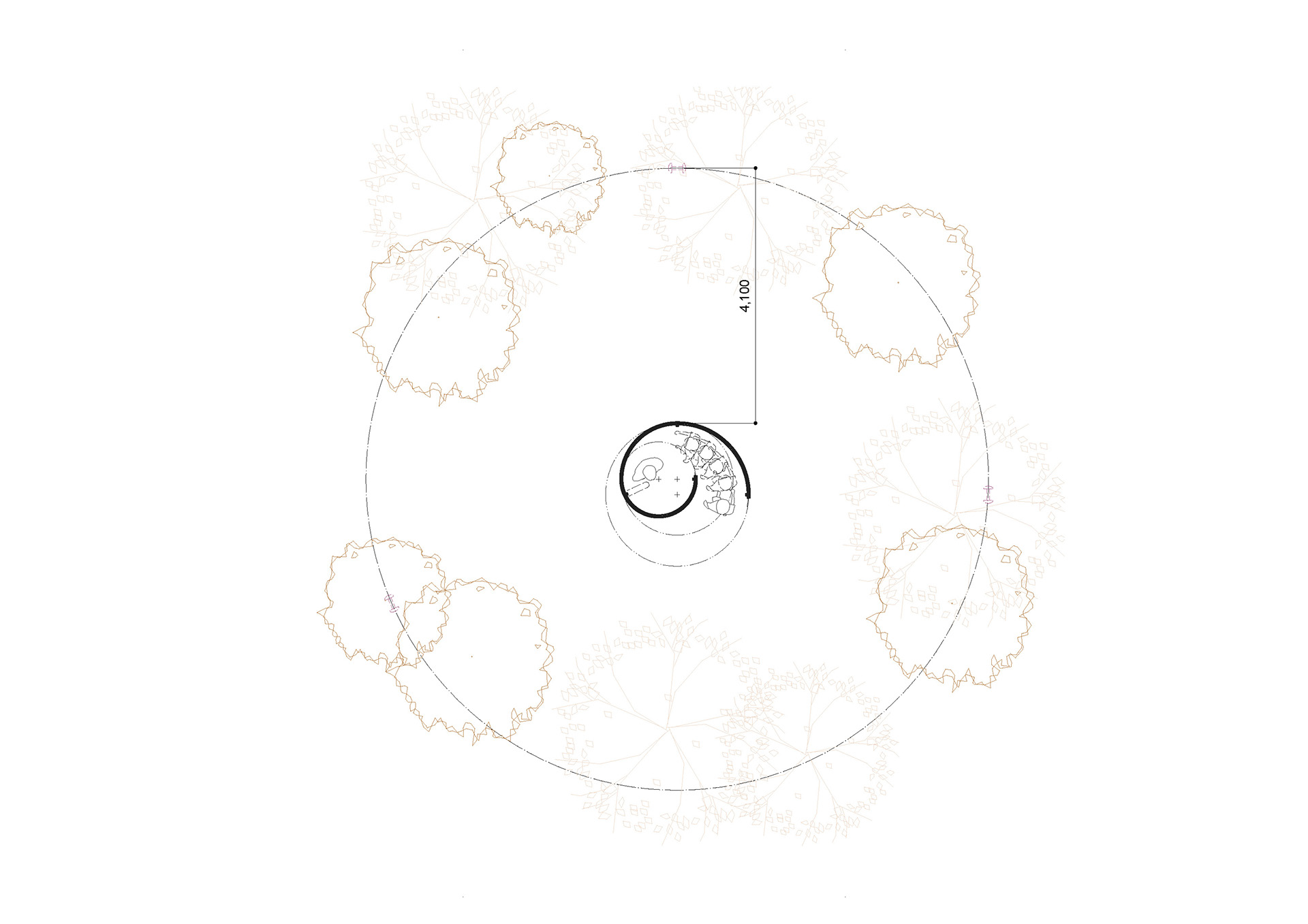
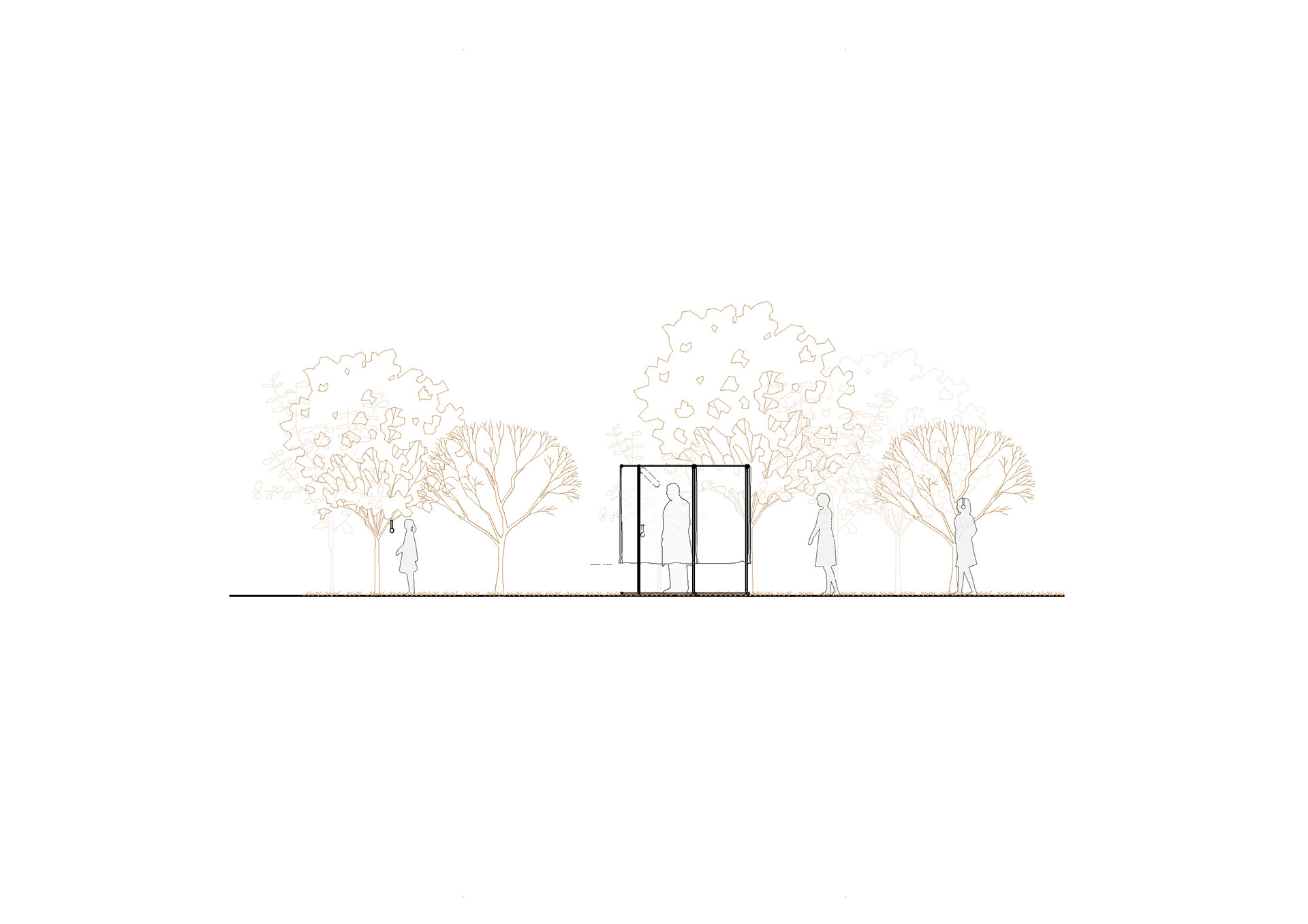
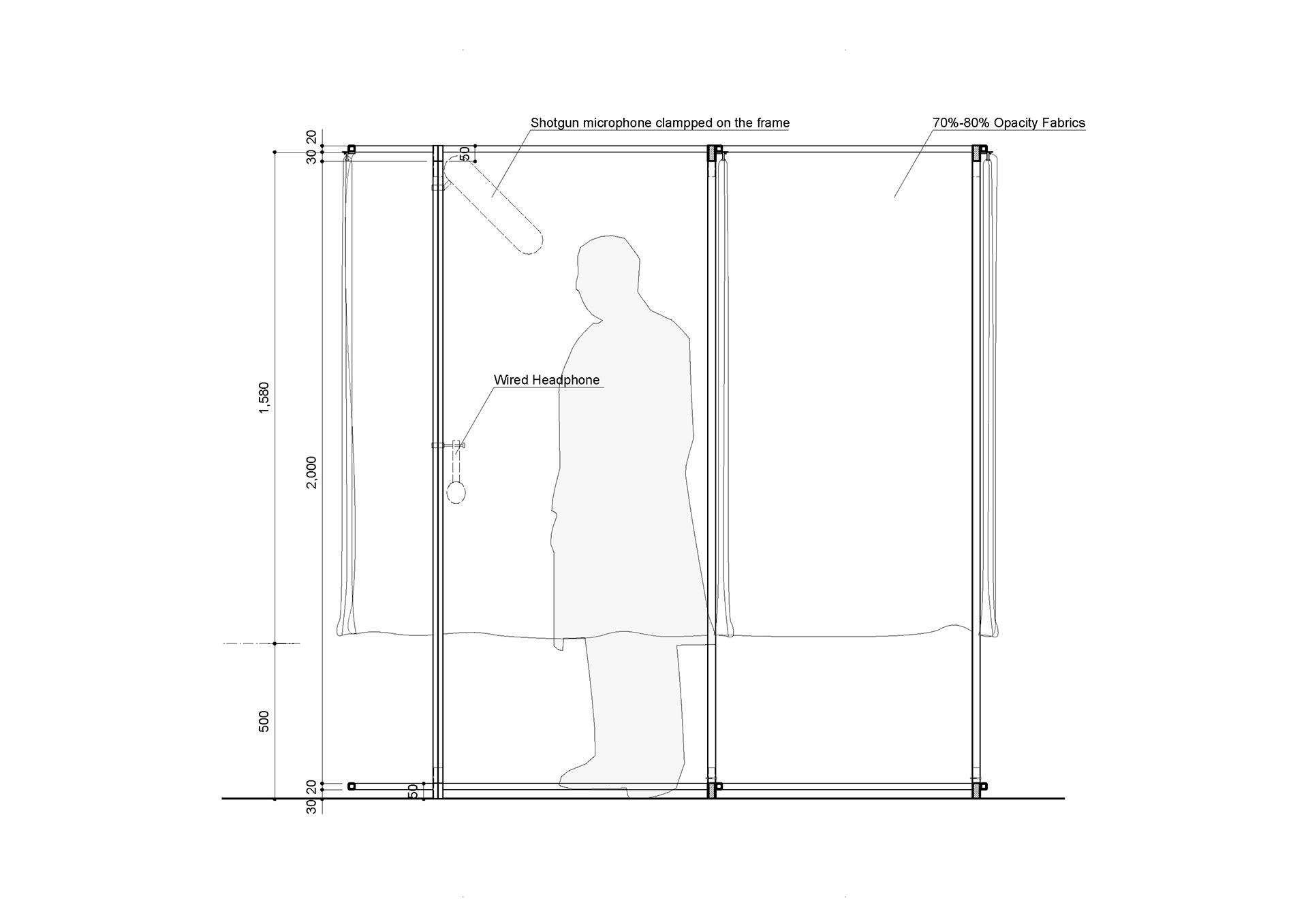
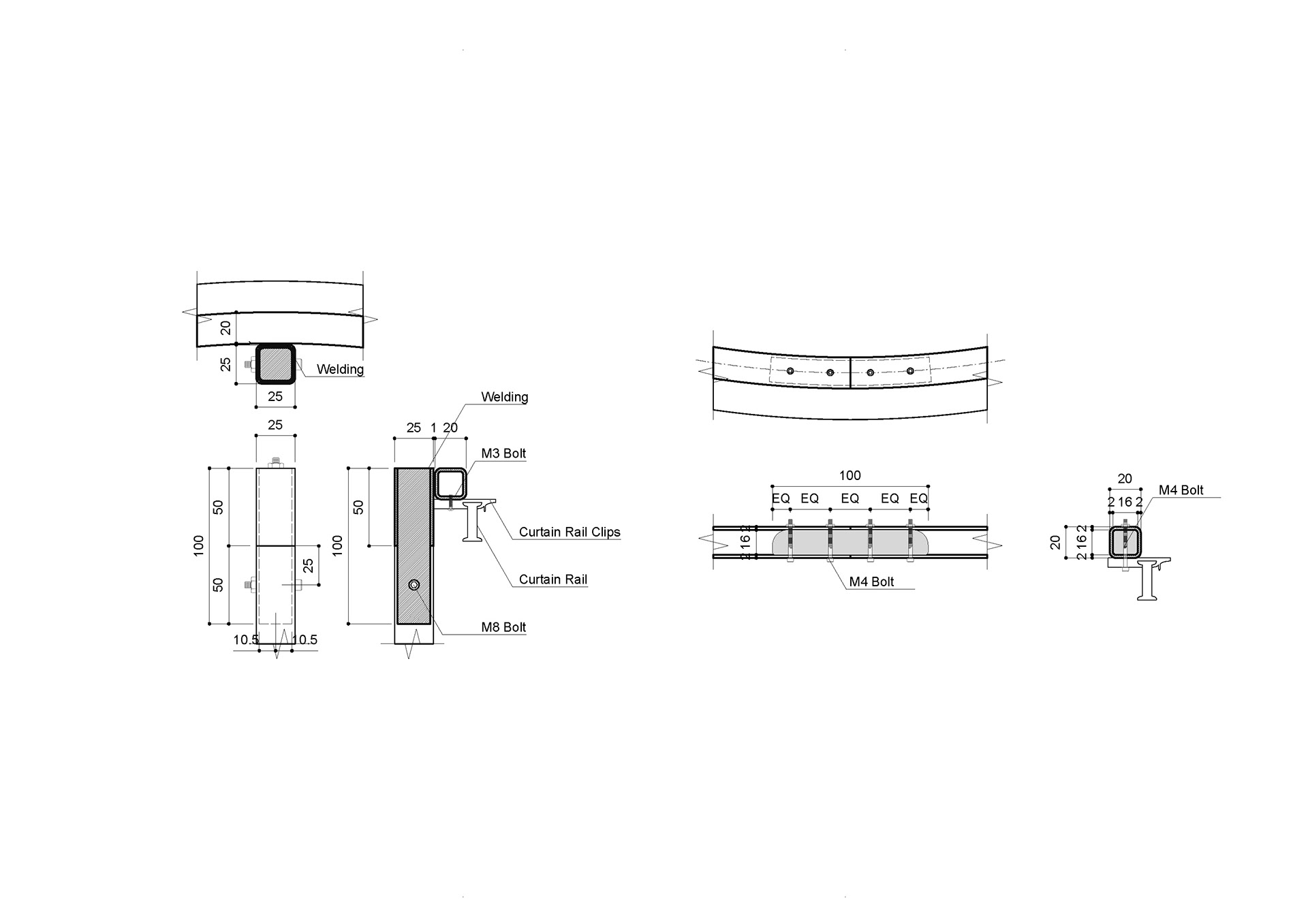
Drawings
Process Film